一、前情提要
1、什么是RAFT
RAFT-stereo是基于RAFT的扩展。RAFT即Recurrent All-Pairs Field Transforms,是一个很出名的光流估计模型,他的特点是先建立全局匹配关系,再通过循环迭代不断细化结果,每一步更新都会变得更准,而RAFT-stereo是基于这个模型的双目改造。
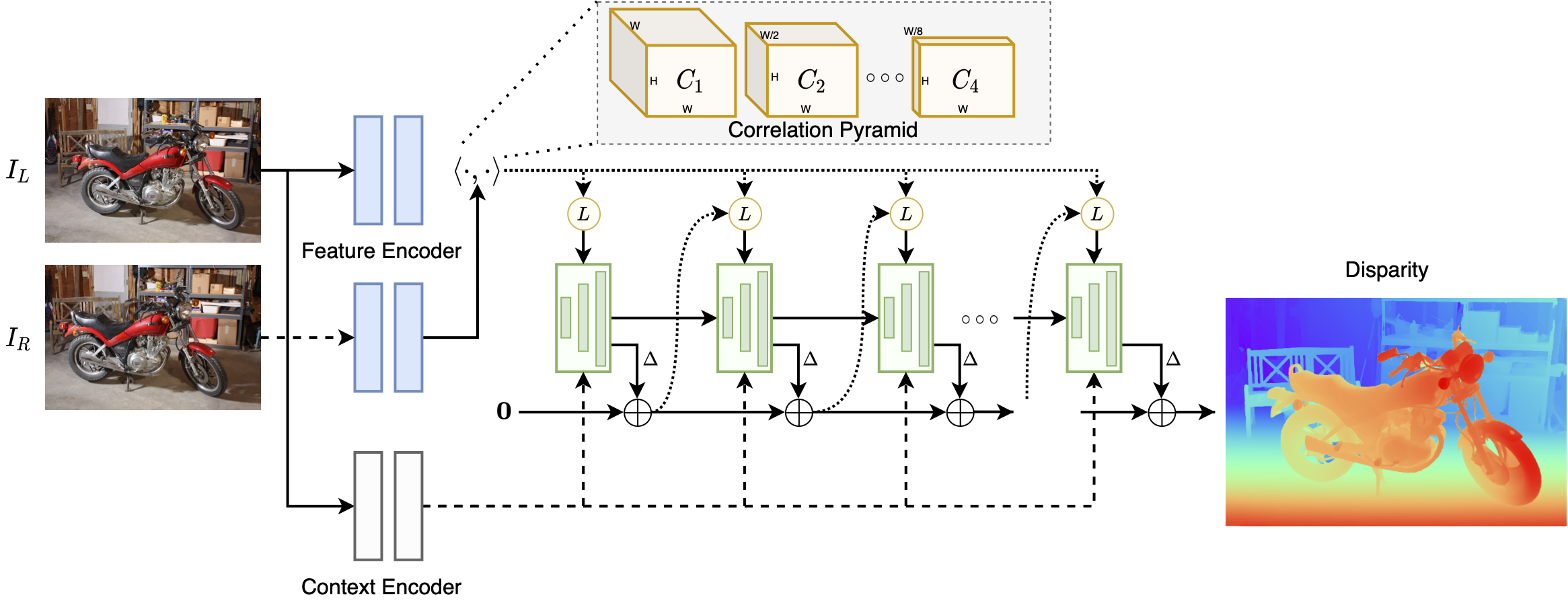
2、RAFT-stereo的原理
先用卷积网络提取左右图的高维特征,而不是拿RGB去比较。因为原始RGB容易受到光照,纹理,噪声影响。 接着就是构建相关性体,简单说就是对于左图中的每一个位置,它都会和右图的一整条去进行相似度比较,形成一种“匹配代价”。 再接着就是不断迭代,他会先给个初始估计,然后通过循环更新模块来反复修正。
3、和其他立体匹配有什么不同之处
传统方法,比如SGM、Blocking Matching,是先算匹配代价,再代价聚合,再做视觉选择,最后再做左右一致性检查。 而RAFT-stereo,属于端到端的学习方法,他会自动学习,什么特征适合匹配,什么区域应该相信上下文,哪些遮挡、弱纹理、重复纹理区域该怎么处理。
4、为什么做这个
我的本科毕业设计做的是双目摄像头的,通过资料搜集,我发现网上感觉最新(2021年提出)的双目摄像头立体匹配算法就是这个RAFT-Stereo,于是我便接触到了这个项目。
二、训练过程
首先,这个项目已经被开源到Github,而且readme文档有较为详细的指令包括下载数据集,demo输出,train,evaluate等等。 说实话,这是我第一次进行正式的模型训练和微调项目,之前做过的模型训练是yolov5,之前g308(西南交通大学robocon校队,我梦开始的地方,没有这个机会,我根据不会接触技术路线,这个博客也不会诞生)的入队考核需要通过这个进行蓝球,红球,球框额的识别(实际上就是robocon2024的麦穗题目),每个人都会以自己的方式接触到yolo,都是回忆啊,在这个之后我就没有做过需要模型训练的项目了,而且就算是那个yolo项目,我也没有进行模型微调,毕竟是入队考核,还是以基础为主。 通过这个项目,chatgpt辅助我,让我也学会了大致的模型微调流程,以下是我的总结
- 首先要对原始模型进行推理和评测,得到baseline,也就是整个微调的基线。
- 然后控制变量,每次只改一部分,而且要保留原模型,改动要作为一个选择,也就是作为运行程序的一个可选参数,而不能直接在原模型上改,不然的话,感觉就没有回头路了。
- 再然后就是根据评价指标,对得到的模型进行评价,和baseline对比。
三、模型改进改动
对于模型改变,我只是根据chatgpt给的提示作了一些修改,代码全部上传到我自己fork的github上,
1.refinement
我首先尝试了增加一个refinement层,这是一个很微小的改变,以下为refinement层
import torch
import torch.nn as nn
import torch.nn.functional as F
class RefinementHead(nn.Module):
def __init__(self, in_channels=4, hidden_dim=32):
super(RefinementHead, self).__init__()
self.conv1 = nn.Conv2d(in_channels, hidden_dim, 3, padding=1)
self.conv2 = nn.Conv2d(hidden_dim, hidden_dim, 3, padding=1)
self.conv3 = nn.Conv2d(hidden_dim, hidden_dim, 3, padding=1)
self.conv4 = nn.Conv2d(hidden_dim, 16, 3, padding=1)
self.conv5 = nn.Conv2d(16, 1, 3, padding=1)
def forward(self, image1, disp):
x = torch.cat((image1, disp), dim=1)
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
x = F.relu(self.conv4(x))
res = self.conv5(x)
return disp + res
实际上RAFT-Stereo最核心的组件就是内置的精炼层—-多层卷积GRU,这样的设计本身就是在精炼,所以第一步的视差估计都是粗糙的,每一步都在上一步的基础上迭代、修正,最后一轮的输出就是经过了32次迭代的输出。 refinement是什么,本质上是一个输出端的残差修正模块,在RAFT-Stereo经过多次迭代后,会输出一个目前比较好的视差图,然后再和输入的左图拼接,
- 左图:3通道
- 视差图:1通道 得到了一个4通道的输入,将其输入到refinement head模块中,就是上面的代码块中,最终得到一个1通道残差图,每个像素点表示此处应该对视差作出的更改。
if hasattr(self.args, 'use_refinement') and self.args.use_refinement:
disp0 = flow_predictions[-1]
disp_refined = self.refinement_head(image1_raw / 255.0, disp0)
else:
disp_refined = flow_predictions[-1]
我的refinement主要想解决的问题是物体边界存在模糊、细节构区域。所以这个模块更像是图像引导的局部视差修正器。
2.边缘感知损失
边缘感知损失本质上让模型在图像边缘附近犯错时付出更大的代价。将普通的L1 loss计算从$L= |d_{pred}-d_{gt}|$ 变成 $L_{edge}=weight*|d_{pred}-d{gt}|$
if args.use_edge_loss:
loss_edge = edge_aware_loss(disp_refined, flow, valid, image1)
loss += args.lambda_edge * loss_edge
metrics["loss_edge"] = loss_edge.item()
那么问题是,如何找到图像边缘位置呢,按照以下步骤:把RGB转成灰度图->算出图像梯度->归一化->构造最终权重。 最终权重计算公式:
$$ weight = 1.0 + \alpha *grad $$该方法的原理是,视觉误差并不是所有位置都一样重要,在平坦区域,误差稍微大一点,视觉上可能还不明显。但在边界区域,只要错一点点,就会造成:
- 轮廓糊掉
- 深度断层错位
- 物体边缘拉扯
- 细结构消失
我的代码整个总损失是由三部分组成,首先是原始的sequence loss,是RAFT-Stereo自带的损失,其次是refined loss,是最终的视差图和gt的普通误差监督,最后是edge-aware loss,这个是对 disp_refined 在边缘区域加权后的误差监督。
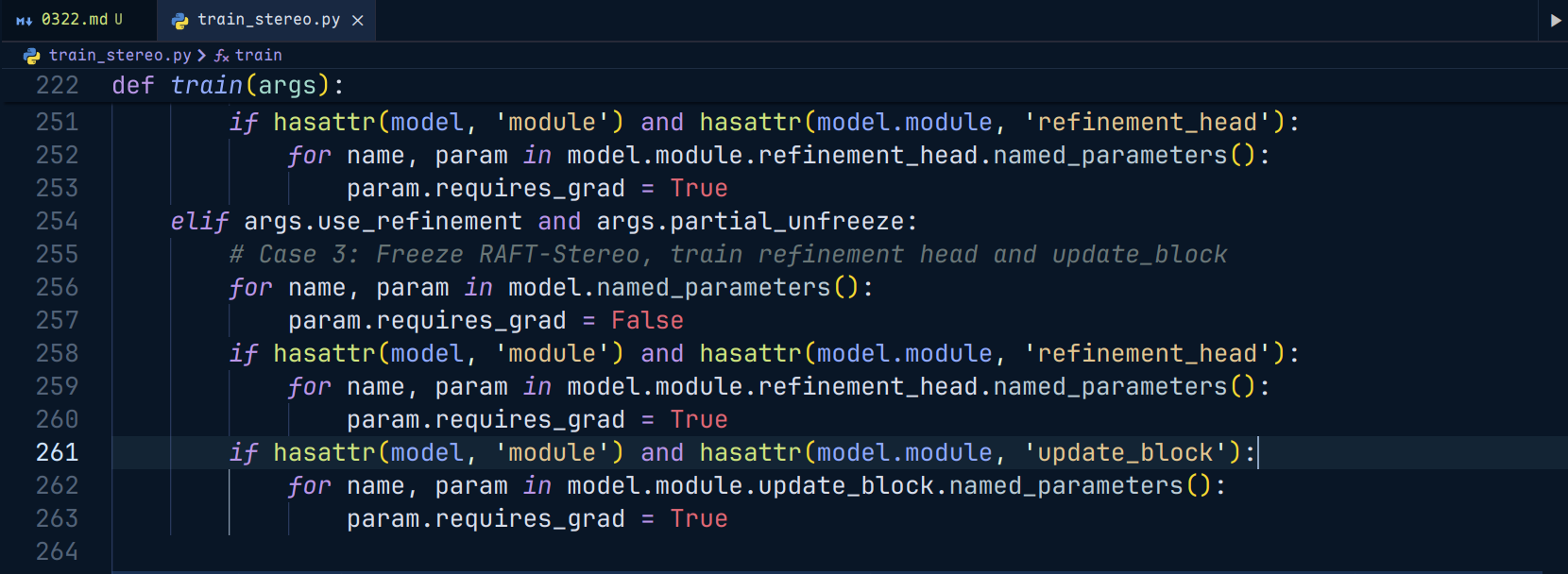
3.partial unfreeze
之前的训练都是冻结整个RAFT-Stereo主干,之训练了新增的,refinement head,但是partial unfreeze呢,仍然保留大部分主干冻结,额外解冻update_block,让refinement_head和update_block一块训练。
四、实验结果
| EPE | D1 | |
|---|---|---|
| Baseline | 2.3758 | 12.0526 |
| Refinement only | 2.3760 | 12.0609 |
| Refinement + Edge Loss | 2.3757 | 12.0588 |
| Partial Unfreeze | 2.4376 | 12.5331 |
从结果可以看出,仅增加 refinement head 或加入边缘感知损失后,模型整体性能与 baseline 基本持平,未出现明显提升,但也没有显著破坏原始模型性能。这说明输出端的轻量级局部修正结构在当前小规模真实域数据集设置下,对整体 EPE 和 D1 指标的影响较为有限。
相比之下,partial unfreeze 策略使模型性能出现明显下降。这说明在仅使用 Middlebury 小规模数据集进行微调时,解冻 update block 会显著增加过拟合风险,并可能破坏原始预训练模型已经形成的匹配更新能力,导致整体泛化能力下降。
五、后续
在尝试提升模型性能无望后,我和导师商量过后决定把研究中心转移到对模型的轻量化上面来,当前模型大概有11.14m个参数,可以尝试剪枝和蒸馏,对模型进行“减重”,方便模型部署到低算力的边缘设备上。
六、碎碎念
我这次训练都是使用autodl的服务器(不是广告),原本我以后这种租服务器,每次都是要把数据上传到服务器端,然后再开始跑模型,受限于网速,每次部署都会很浪费时间,如果一直挂着服务器,钱包又会受不了。实际上,这个服务器端,有三种存储形式,系统盘,数据盘和文件存储,其中系统盘就是镜像装配的盘,也就是整个系统配置所在的盘,你可以把一些数据文件放在里面,但是这个盘的大小通常不大,所以大数据不适合放在里面,但是这个有一个很大的有时就是,你可以上传自己的容器示例。
 上传的实例可以非常方便的部署到同型号或者近似型号的显卡上。
上传的实例可以非常方便的部署到同型号或者近似型号的显卡上。
总算可以好好休息一下,前段时间还是有点太忙了。